Data science projects aren’t what they first appear.
Many data scientists believe data science is about solving problems using statistics and models. But those are likely the same data scientists whose projects never make it into production.
Because if you’re a data scientist working on a project and stop after creating a data solution, you’re only half done. And stopping a project when it’s half done is like taking a cake out of the oven when it’s only half cooked. It might look great on the outside, but you can’t do anything with it – except put it back in the oven.
I’ve spent my entire career solving problems with data and seen the value data science can bring. But to create that value, you need to change your perspective on data science.
Every Successful Data Science Project Addresses Two Problems
Data science projects that deliver business value solve two interrelated problems: a business problem and a data problem.
A business problem is any challenge or issue faced by a business. For example, finding customers, increasing profits or building brand awareness. Not every business problem is solvable using data.
Data problems are the sorts of problems you encounter on Kaggle or in data science courses. Data problems include things like:
- Predicting future outcomes given current data;
- Automating repetitive processes around data; and
- Identifying and interpreting patterns and trends present in a data set.
Solving data problems is why most people go into data science in the first place.
Considering a data problem on its own is fine in an educational setting but leads to waste in business. This is what happens when organisations hire data scientists and tell them to “go do data science.”
Successful data science projects begin with the identification of a business problem. This business problem then informs a data problem. Relevant data is acquired. Then the data is used to create a data solution that also solves the business problem.
This is illustrated in the diagram below.
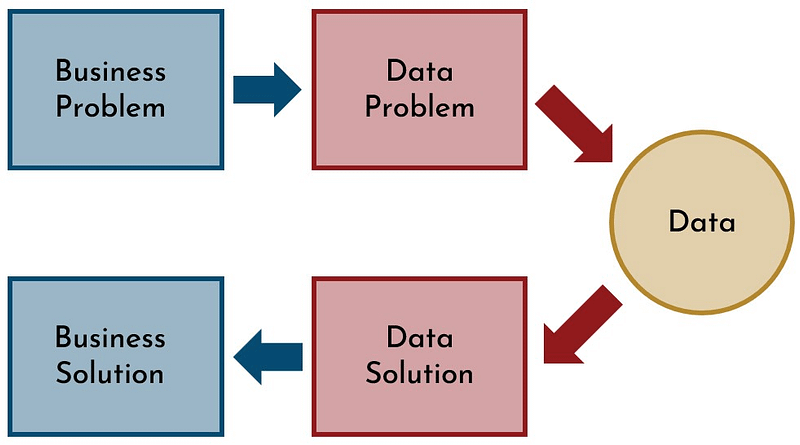
Data science projects that address both a data problem and a business problem are more likely to make it into production. Yet, many data scientists still focus solely on data problems.
Here are two reasons why.
Team Silos Create Knowledge Gaps
Data silos are bad for data science. They make it difficult to connect disparate datasets.
When data science first took off, data silos were one of the biggest obstacles to success. Without the necessary data architecture in place, data scientists were limited in what they could deliver. Businesses learned the error of their ways. And now, data consolidation is seen as a necessary first step when building a business’s data capabilities.
Yet, data silos are not the only silos hindering effective data science. Team silos are just as bad. And while most organisations recognise the dangers of team silos, many have yet to address them.
Team silos occur when a team becomes disconnected from the rest of the business. For some teams, this might not be an issue. However, when data professionals become disconnected from the business, knowledge gaps occur.
The consequence of such knowledge gaps is described by Danny Samson, Alon Ellis and Stuart Black in Business Model Transformation: The AI & Cloud Technology Revolution, in the context of artificial intelligence (AI):
"The product leader might want AI to do something, but they don’t know what is possible. The subject matter expert AI analyst wants to do something, but they do not understand the customer problem. So you just have these two wheels spinning and an interface between them that is just pure gridlock."
When knowledge gaps exist between data scientists and the business, data problems and business problems inevitably become disconnected.
Shiny, New Toy Syndrome Doesn’t Help
Data science is still seen as a shiny, new toy by many organisations. Especially when it comes to cutting-edge techniques, such as deep learning.
As data science educator, Amanda Aitken, expressed in my podcast, Value Driven Data Science:
"Sometimes we get a bit carried away with the newest thing to play with when maybe simple linear regression or a GLM might be just as good."
This is true of both data scientists and business leaders.
Data scientists want to play with the latest technologies. This is one of the biggest drawcards an employer can offer to attract talent. But many business leaders also love speaking of the new technologies being used in their business.
This can lead to a “hammer in search of a nail” situation. By actively searching for ways to use a particular technique, data scientists and business leaders place undue focus on data problems, at the expense of business problems.
Even when data problems and business problems are connected, this mindset can lead to unnecessarily complicated data solutions. And that can lead to suboptimal solutions to business problems.
To improve the success rate of data science projects, organisations should, therefore, focus on addressing any knowledge gaps that exist between data scientists and the business, and placing the focus of any data science projects first and foremost on solving business problems.
Bridging Knowledge Gaps Between Leadership and Data Science
To bridge the knowledge gap between data scientists and the business, data scientists need to become more business literate. But business leaders also need to become more technologically literate.
To become more business literate, data scientists need to interact with the business. Embedding data scientists within business units can help. But regardless, all data scientists need to regularly talk with their end-users. They need to understand their pain.
Some of the most effective data scientists I’ve met began as technology end-users. They understand their end-user’s needs because those needs used to be their own. Data scientists who can put themselves in their end-user’s shoes typically deliver better solutions.
Yet, bridges extend both ways. Business leaders need to be able to communicate with data professionals, and make informed and effective strategic decisions in the technology space. This requires technological literacy.
What technological literacy means will vary by organisation. Yet, it should include a high-level understanding of the building blocks of data solutions, and the strengths and weaknesses of any relevant technologies. Just as data scientists need to interact with the business, business leaders need to regularly talk with data scientists.
Business leaders don’t need to be able to produce data solutions any more than data scientists need to be able to run the business. But each party needs a basic understanding of their counterpart’s area of expertise.
Once the knowledge gap is bridged, business leaders and data scientists can work together to identify business problems suitable for being solved using data science. This can be done using data science project discovery.
What is Data Science Project Discovery?
Data science project discovery involves identifying and understanding the problems of greatest business importance, and then considering the feasibility of a data science solution to those problems.
I outline this process in detail in a FREE guide you can download here.
At a high level, the process involves four steps:
1. Identify Key Business Problems
Assess your current business situation and identify the key problems you currently face.
For example, three problems a business might currently face could be:
- reducing the error rate when manually classifying documents based on relevancy;
- dealing with reputational damage following unfavourable media coverage; and
- predicting future movements in the stock price of the business and its competitors.
2. Determine Data Science Suitability
Take the problems identified in Step 1 and assess whether they are suitable for solving using data science. Ignore feasibility at this step.
The aim is to identify problems that sit at the intersection of those that (a) matter to the business and (b) are suitable for solving using data. This is illustrated below.
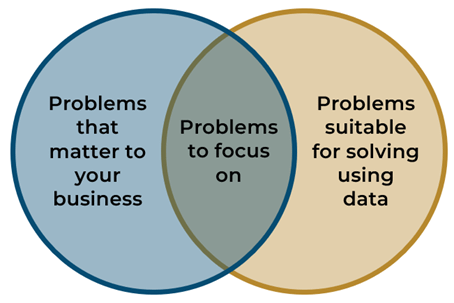
3. Assess Feasibility and Importance
Rate the feasibility and importance of the problems identified in Step 2 on a three-point scale (i.e. high, medium and low). Then use these ratings to rank the identified problems.
The greater the feasibility of a problem and the greater its importance to the business, the more likely it is to succeed. So, its ranking should be higher.
For example, although predicting stock prices using data is possible, doing so with high accuracy is very challenging. It typically requires specialist financial knowledge. So this problem may be given a low feasibility rating.
If the relevancy of documents is based on a simple rule set, on the other hand, reducing classification errors through automation is highly feasible.
4. Define your Vision of Success
Define what a successful solution looks like from a business, rather than a technical, point of view. This includes understanding such items as:
- business objectives to be met;
- metrics for success;
- the value to the business of solving the problem; and
- any risks or business constraints that exist.
The data science project discovery process leads to the creation of data science projects that focus on what is of greatest importance to the business.
Defining a vision of success reduces shiny, new toy syndrome, since it places parameters around solutions. And if data scientists work through this process alongside business leaders, team silos are also reduced.
Data Science Doesn’t Solve Problems – People Solve Problems
On their own, data, technology and data science don’t solve problems. They enable people to solve problems. And data science projects ultimately exist to address issues of importance to the business.
Data scientists are worthless if they exist as islands within an organisation. For data science to succeed, bridges need to be built between data scientists and the rest of the business. And both data scientists and business leaders are responsible for this.
As we enter into the age of data, data science has a lot to offer. It just has to be used to solve the right problems.
